LOGSTASH HTTP INPUT STRESS TESTING
 In a perfect world, every little thing in a data pipeline would be thoroughly tested with regard to efficacy/capacity/efficiency blah blah blah, ad infinitum.
In a perfect world, every little thing in a data pipeline would be thoroughly tested with regard to efficacy/capacity/efficiency blah blah blah, ad infinitum.
In reality, operators need to get shit done, and get it done yesterday.
So we wanna test the HTTP input, what do ?
TERMS
- Events Per Second (eps, e/s, events/s)
- Systme Under Test (SUT)
QUESTIONS TO ANSWER
- What’s the maximum eps value we can achieve in our own lab?
- What’s a normal / ok eps value?
- Does the input have any settings that can be used for PERFTUN?
METHODOLOGY
In general we should adhere to the following
-
KISS (keep it simple stupid)
- starting with the minimal config from a logstash settings perspective is often preferable
- for example
input { http { port => 1313 threads => 2 } }- would be preferred over
input { http { port => 1313 ecs_compatibility => 'v8' response_code => 202 response_headers => { 'content-type' => 'text/plain' } threads => 32 } } -
Use small / medium / large settings.
- this is kinda analagous to unit testing where we would test a function that takes an integer with inputs: [-1, 20, 10000]
- in logstash land settings like threads or pipeline.workers default to the # of cpu cores
- pipeline.batch.size defaults to 125
- in a production config it’s not uncommon to have multiple logstash pipelines running per given logstash host and if each pipeline is using the default # of threads or workers, we could see CPU contention
- starting with small settings like
threads => 2andpipeline.workers: 2and seeing the max throughput that can be achieved for the given system can give is a baseline and help us better judge where we might need to tune up these settings - using very incremental settings is often a waste of time in that we don’t gain any large diff in eps; the insight gained isn’t that valuable compared with a small/medium/large approach
- i.e. if we’re testing effects of
pipeline.batch.sizeon eps, we’ll be better served by using test values of [125, 500, 2000] than we would using values like [125, 150, 200, 250, 300, 350, 400, 500..2000] - 125 is the default so that means we would have a minimal config and only need to explicitly declare the
pipeline.batch.sizetwice
- i.e. if we’re testing effects of
-
CHANGE ONE THING AT A TIME => MEASURE
- if anything this is just all caps to remind us to try and adhere to this.
- in practice it’s much harder to adhere to especially when you’re in the zone freestyling, changing files on the fly, firing off scripts, pivoting to monitoring, tailing files, having eureka moments, having false eureka moments, having OH SHIT moments etc.
- if we had a nickel for every time we thought we were testing one thing, only to find out we forgot we left old configs in place, and now we’re back at square one, unsure if the spike in eps we saw was the combination of
threads => 24 && pipeline.bath.size => 1000 || just pipeline.batch.size => 1000 || threads => 24
-
Start off with a small logstash conf and tune up
- this has some crossover with the above topics mentioned.
- this helps us assess how well our needs can be served by a given config
- i.e. if our upstream client is only sending us 100 eps, do we really need to tune up for logstash to handle 5K eps?
- is the message rate bursty ?
- what does an overwhelmed input look like to an operator, outside the obvious (i.e. crash or otherwise messages go dead, EPS == 0)
STRESSOR ?
- We have been well served in the past by using an external Logstash node with a generator input to send output to the SUT.
- We’re gonna deviate from that here because SIEGE exists and it’s much more straightforward to run a single command to generate HTTP load than it is to go through setup of a logstash stressor
TEST CASES
Test cases are intertwined with combinatorial math (gross).
We’ll have the following categories of variables all with 3 options
- JVM HEAP
- PIPELINE BATCH SIZE
- PIPELINE WORKERS
- HTTP THREADS
- SIEGE CONCURRENCY
- SIEGE PROCESSES
We have 6 variables each with 3 possible values, where repetition is allowed and order matters, so we have 3^6 possible cases == 729 WOOOOMP.
To generate test cases we can just use nested for loops… weeeee

#!/usr/bin/env python3
JVM_HEAP = [1,4,8]
BATCH_SIZE = [125,500,2000]
WORKERS = [2,8,16]
HTTP_THREADS = [2,8,16]
SIEGE_C = [10,50,100]
SIEGE_PROC = [1,3,5]
print('TEST_CASE,JVM_HEAP,BATCH_SIZE,WORKERS,HTTP_THREADS,SIEGE_C,SIEGE_PROC')
TESTCASE=1
for j in JVM_HEAP:
for b in BATCH_SIZE:
for w in WORKERS:
for h in HTTP_THREADS:
for c in SIEGE_C:
for p in SIEGE_PROC:
test_case=f'TC-{TESTCASE}'
print(f'{test_case},{j},{w},{b},{h},{c},{p}')
TESTCASE+=1
Ok so we know what our test cases look like… now we need away to set this and forget this so the test cases can run. We’ll use the same loop structure as before but for each iteration we’ll need to do the following.
- Spawn logstash with the relevant settings and ensure it becomes available before siege (otherwise siege will exit).
- Spawn siege consistent with the test cases (do we need 1, 3, 5 processes?)
- Let the test run for some time; we chose 5 minutes
- Kill the logstash and siege processes and sleep a bit to ensure clean shut down.
We can do this in bash
- This version is ok
- BETTER
- START_AT arg?
- what if something goes awry in the middle of testing? in the current state we’d queue up everything all over again, which isn’t optimal.
- take an arg that’s used to start at x test case would allow us to start on the next good test case
- i.e.
./stress.sh 13$BIG_NASTY_NESTED: if tc < $START_AT { skip } else { test()}
- test case in document body ?
- putting the test case sequence in the document would be an additional measure to ensure we’re testing the right settings for a given test case; at least as far as which variables we were using.
- if we did that we would post a json document with siege but we’d have some additional setup to ensure that the document gets parsed appropriately, and then we’d have to make sure we retrieved the right results.
- START_AT arg?
#!/bin/bash
### Usage: generate stress on a logstash node....
# tl/dr given all input variables we have 730 test cases that need to be executed.... that's a lot
# - we need an automation component to do this at scale without going insane
# - JVM_HEAP_GB
# - 1,4,8
# - BATCH_SIZE
# - 125,500,2000
# - WORKERS
# - 2,8,16
# - HTTP_THREADS
# - 2,8,16
# - SIEGE_C
# - 1 50 100
# - SIEGE_PROC
# - 1, 3, 5
#
JVM_HEAP=(1 4 8)
BATCH=(125 500 2000)
WORK=(2 8 16)
HTTP_THREADS=(2 8 16)
SIEGE_C=(1 50 100)
SIEGE_P=(1 3 5 )
ESTC_PASS="CRED_HERE"
ESTC_HOST="localhost:9200"
OUTPUTS_FILE=/tmp/runs.log
RUN=1
for j in ${JVM_HEAP[@]} ; do
for b in ${BATCH[@]} ; do
for w in ${WORK[@]} ; do
for h in ${HTTP_THREADS[@]} ; do
for c in ${SIEGE_C[@]} ; do
for p in ${SIEGE_P[@]} ; do
#### start logstash in the background because it has to be available or siege will exit
echo "ENTERING TC-$RUN:" JVM:$j, BATCH:$b, WORKERS:$w, HTTP_THREADS:$h, SIEGE_C:$c, SIEGE_PROCS:$p
echo "============================================================================="
LS_JAVA_OPTS="-Xmx${j}g -Xms${j}g" /usr/share/logstash/bin/logstash -e "input { http { port => 6003 threads => $h } } output { elasticsearch { hosts => [\"$ESTC_HOST\"] user => elastic password => \"$ESTC_PASS\" index => \"logstash-http\"}}" -b $b -w $w --log.level warn --path.logs /tmp/run_logs &
sleep 20
for i in {1..$p}; do
#echo "siege -$c http://localhost:6003/_new_doc POST TC-$RUN"
siege -c $c "http://localhost:6003/_new_doc POST \"TC-$RUN\"" &
done
sleep 300
RUN=$((++RUN))
ps aux | grep java | grep logstash | grep -oE '^root\s+[0-9]+'|sed -E 's/root\s+//g'|while read i ; do kill -9 $i ; done
sleep 3
echo "============================================================================="
echo
sleep 15
done
done
done
done
done
done
Now we need a way to snag our results after the tests have run…python to the rescue
#!/usr/bin/env python3
import json
import requests
"""
USAGE:
- query the results of our logstash test runs
- GET _COUNT $TESTCASE
- GET MIN(timestamp)
- GET MAX(timestamp)
- DIFF SECS (max - min) / 1000
- EPS = COUNT / SECS
"""
ES_HOST='http://localhost:9200'
ES_INDEX='logstash-http'
ES_CRED=('elastic','CRED_HERE')
QUERY_COUNT = {
'query':{
'bool':{
'filter':[{'match':{'message.keyword':'"TC-1"'}}]
}
}
}
QUERY_MAX= {
'query':{
'bool':{
'filter':[{'match':{'message.keyword':'"TC-1"'}}]
}
},
'size':0,
'aggs':{
'mx':{
'max':{
'field':'@timestamp'
}
}
}
}
QUERY_MIN = {
'query':{
'bool':{
'filter':[{'match':{'message.keyword':'"TC-1"'}}]
}
},
'size':0,
'aggs':{
'mn':{
'min':{
'field':'@timestamp'
}
}
}
}
def get_results(tc):
try:
QUERY_COUNT['query']['bool']['filter'][0]['match']['message.keyword'] = f'"TC-{tc}"'
QUERY_MIN['query']['bool']['filter'][0]['match']['message.keyword'] = f'"TC-{tc}"'
QUERY_MAX['query']['bool']['filter'][0]['match']['message.keyword'] = f'"TC-{tc}"'
count_result = requests.get(f'{ES_HOST}/{ES_INDEX}/_count',auth=ES_CRED,json=QUERY_COUNT)
if count_result.status_code == 200:
data = count_result.json()
count = data.get('count')
min_res = requests.get(f'{ES_HOST}/{ES_INDEX}/_search',auth=ES_CRED,json=QUERY_MIN)
if min_res.status_code == 200:
data = min_res.json()
min_stamp = data['aggregations']['mn']['value']
max_res = requests.get(f'{ES_HOST}/{ES_INDEX}/_search',auth=ES_CRED,json=QUERY_MAX)
if max_res.status_code == 200:
data = max_res.json()
max_stamp = data['aggregations']['mx']['value']
if max_stamp is not None and min_stamp is not None and count is not None:
diff = max_stamp - min_stamp
diff_secs = diff / 1000
eps = count / diff_secs
print(f'TC {tc}: EPS: {eps}')
else:
return False
else:
print(f'failed to get max for tc: {tc}')
print(max_res.text)
else:
print(f'failed to get min for tc: {tc}')
print(min_res.text)
else:
print('FAIL')
print(count_result.text)
except Exception as e:
print(e)
def main():
for i in range(1,730):
get_results(i)
if __name__ == '__main__':
main()
At this point it would be good to estimate how long our test runs will take….
- we have 729 test cases
- each run we sleep the following
- 20 seconds at start of logstash
- 300 seconds after siege is started
- 3 seconds after we kill the java process
- 15 seconds before the next run (necesary? idk..)
- total: 338 seconds
- 338 * 729 cases == 246402 seconds / 60 / 60 / 24 == 2.8518749999999997 days… WOOMP
There’s gotta be additional room for parallelism here but we need more resources for that; between the siege load and everyhing else we’d probably crash something. It would also add more complexity (opposite of KISS) and we can basically set/forget this thing and come back to it.
TEST SYSTEMS
We’re gonna test on a generic base model laptop and beefed up server.
-
RAZER BLADE
- Base model RAZER 15'
- 16g RAM
- 12 cpu
- Single node elasticsearch running on localhost
- Stack version 8.6.2
$ logstash --version Using bundled JDK: /usr/share/logstash/jdk logstash 8.6.2 $ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Address sizes: 39 bits physical, 48 bits virtual Byte Order: Little Endian CPU(s): 12 On-line CPU(s) list: 0-11 Vendor ID: GenuineIntel Model name: Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz CPU family: 6 Model: 158 Thread(s) per core: 2 Core(s) per socket: 6 Socket(s): 1 Stepping: 10 CPU max MHz: 4100.0000 CPU min MHz: 800.0000 BogoMIPS: 4399.99 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 mo nitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_a d fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities Virtualization features: Virtualization: VT-x Caches (sum of all): L1d: 192 KiB (6 instances) L1i: 192 KiB (6 instances) L2: 1.5 MiB (6 instances) L3: 9 MiB (1 instance) NUMA: NUMA node(s): 1 NUMA node0 CPU(s): 0-11 Vulnerabilities: Itlb multihit: KVM: Mitigation: VMX disabled L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable Mds: Mitigation; Clear CPU buffers; SMT vulnerable Meltdown: Mitigation; PTI Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable Retbleed: Mitigation; IBRS Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization Spectre v2: Mitigation; IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS Not affected Srbds: Mitigation; Microcode Tsx async abort: Not affected -
BEEFCAKE
- Dell Server
- 128G RAM
- 48 cpu
- Single node elasticsearch running on localhost
- Stack version 7.17.9
$ logstash --version logstash 7.17.9 $ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 46 bits physical, 48 bits virtual CPU(s): 48 On-line CPU(s) list: 0-47 Thread(s) per core: 2 Core(s) per socket: 12 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel CPU family: 6 Model: 63 Model name: Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz Stepping: 2 CPU MHz: 2070.996 CPU max MHz: 3300.0000 CPU min MHz: 1200.0000 BogoMIPS: 4999.99 Virtualization: VT-x L1d cache: 768 KiB L1i cache: 768 KiB L2 cache: 6 MiB L3 cache: 60 MiB NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46 NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47 Vulnerability Itlb multihit: KVM: Mitigation: Split huge pages Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable Vulnerability Meltdown: Mitigation; PTI Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected Vulnerability Srbds: Not affected Vulnerability Tsx async abort: Not affected Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes6 4 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts md_clear flush_l1d
RESULTS
For the most part, both systems exhbited similar results in that the EPS rate seemed to be tied to the amount of input threads used on the HTTP input; makes sense, more threads == more messages able to be Rx’d.
What was (somewhat?) unexpected was how the EPS rate is about 3x more on beefcake, despite the same process being used for both (albeit different versions). Maybe beefcake, by sheer size, gets more out of threads/cpu than the blade when we consider threads:cpu ratio.
-
blade results sorted by eps
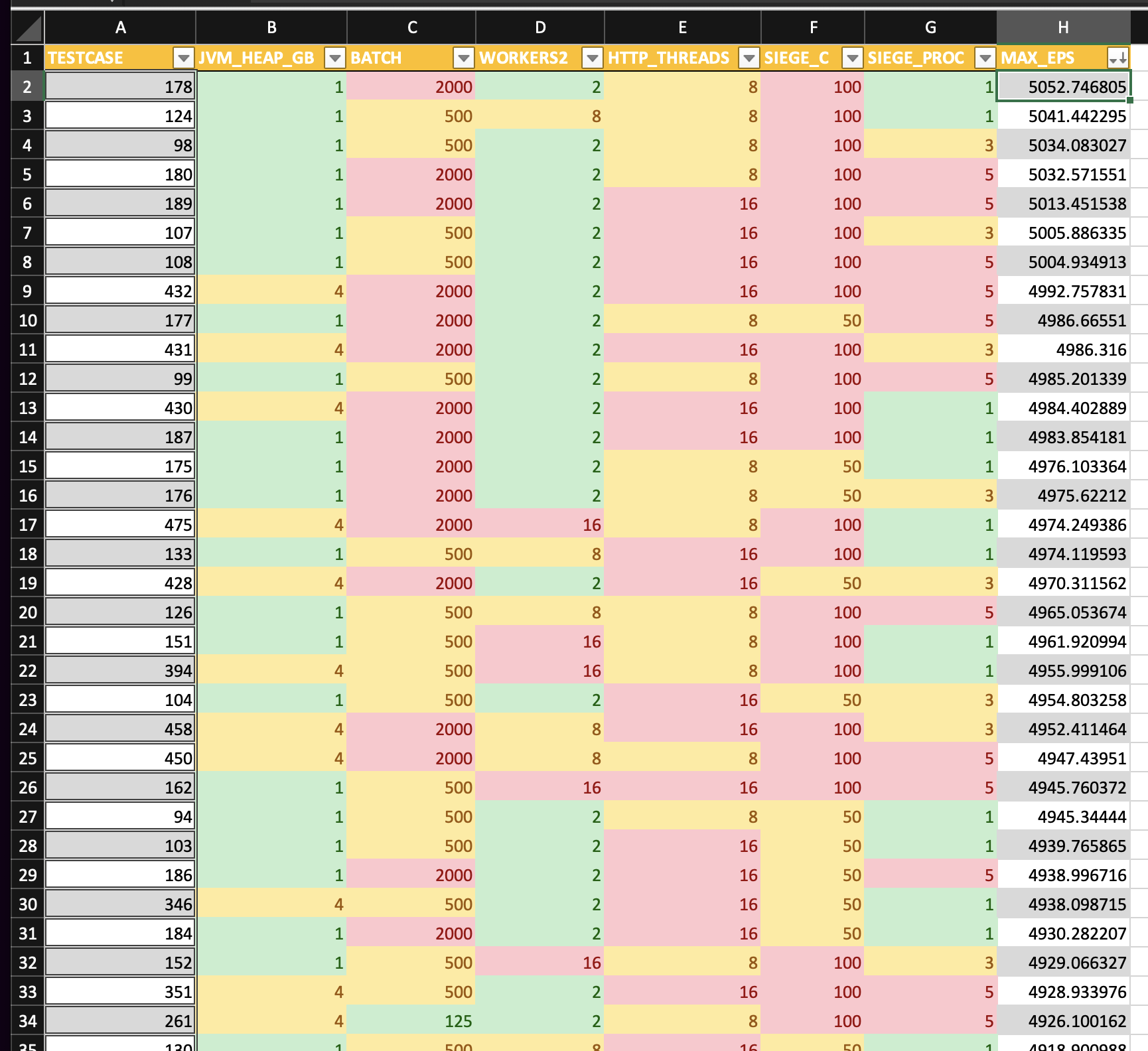
-
beefcake results sorted by eps
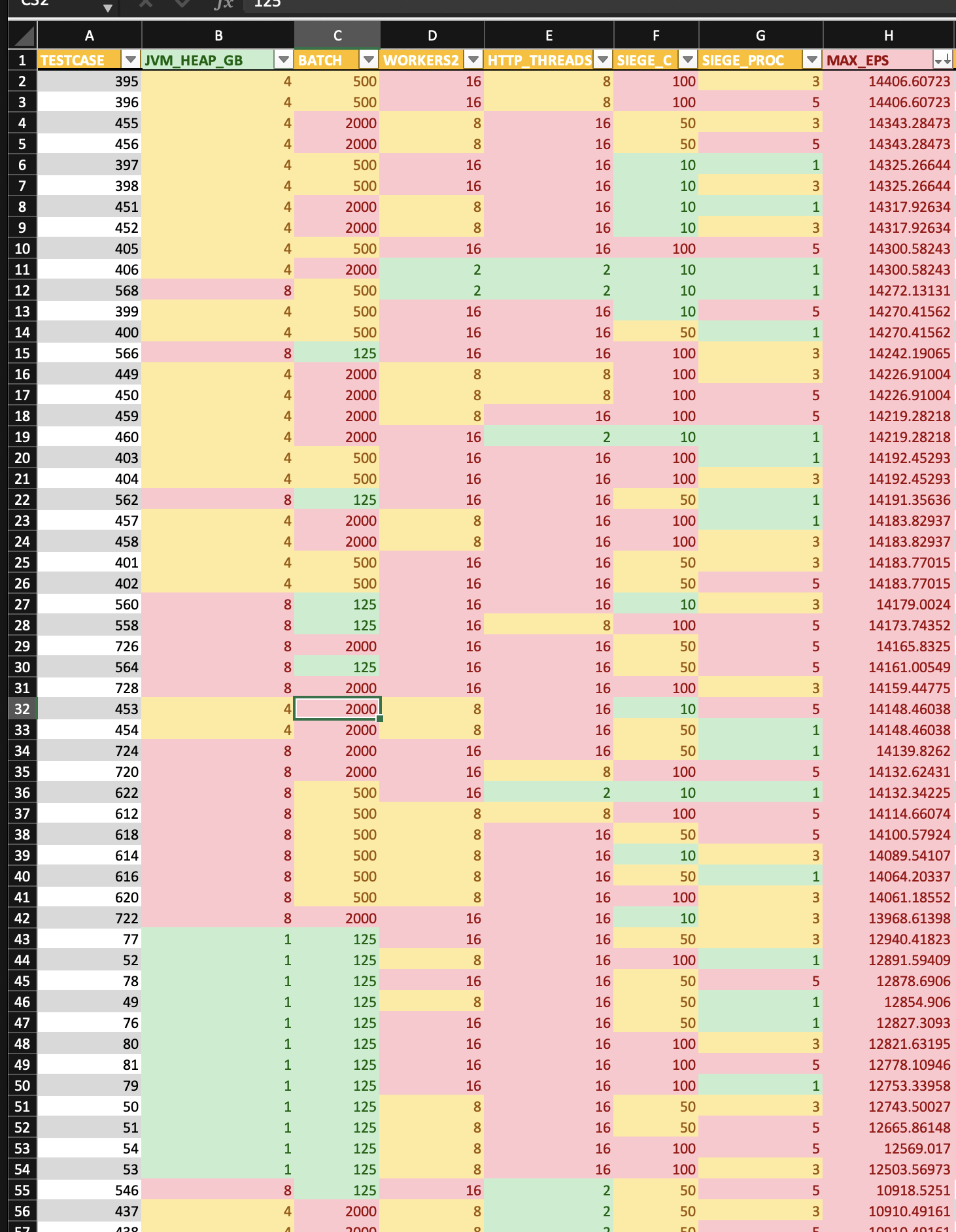
Anyways, happy logging…